Tutorial: Partition your space
Why partitioning the space?
Often the data is not written on disks the way we would like to have it distributed. Re-partitioning the space is a way to re-organise the data to speed-up later queries, exploration of the data set or visualisation.
Unfortunately, re-partitioning the space involves potentially large shuffle between executors which have to send and receive data according to the new partitioning scheme. Depending on the network capacity and the size of the initial data set, this operation can be costly and the re-partition is only a good idea if multiple queries have to be performed, or if you do not have other choices (like in visualisation).
You might noticed the DataFrame API does not expose many things to repartition your data as you would like (unlike the RDD API), hence we decided to bring here new DataFrame features!
How spark3D partitions DataFrames?
The partitioning of a DataFrame is done in two steps.
- First we create a custom partitioner, that is an object which associates each object in the dataset with a partition number. Once this partitioner is known, we add a DataFrame column with the new partition ID (
prePartition). - Second we trigger the partitioning based on this new column (
repartitionByCol) using a simpleKeyPartitioner.
Note that partitioning by a DataFrame column is similar to indexing a column in a relational database.
Available partitioning and partitioners
There are currently 2 spatial partitioning implemented in the library:
- Onion Partitioning: See here for a description. This is mostly intented for processing astrophysical data as it partitions the space in 3D shells along the radial axis, with the possibility of projecting into 2D shells.
- Octree: An octree extends a quadtree by using three orthogonal splitting planes to subdivide a tile into eight children. Like quadtrees, 3D Tiles allows variations to octrees such as non-uniform subdivision, tight bounding volumes, and overlapping children.
In addition, there is a simple KeyPartitioner available in case you bring your own partitioning scheme (see example below).
An example: Octree partitioning
In the following example, we load 3D data, and we re-partition it with the octree partitioning (note that in practice you can have metadata in addition to the 3 coordinates):
// spark3D implicits
import com.astrolabsoftware.spark3d._
// Load data
val df = spark.read.format("csv")
.option("header", true)
.option("inferSchema", true)
.load("src/test/resources/cartesian_spheres_manual.csv")
df.show()
+---+---+---+------+
| x| y| z|radius|
+---+---+---+------+
|1.0|1.0|1.0| 0.8|
|1.0|1.0|1.0| 0.5|
|3.0|1.0|1.0| 0.8|
|3.0|1.0|1.0| 0.5|
|3.0|3.0|1.0| 0.8|
|3.0|3.0|1.0| 0.5|
|1.0|3.0|1.0| 0.8|
|1.0|3.0|1.0| 0.5|
|1.0|1.0|3.0| 0.8|
|1.0|1.0|3.0| 0.5|
|3.0|1.0|3.0| 0.8|
|3.0|1.0|3.0| 0.5|
|3.0|3.0|3.0| 0.8|
|3.0|3.0|3.0| 0.5|
|1.0|3.0|3.0| 0.8|
|2.0|2.0|2.0| 2.0|
+---+---+---+------+
// Specify options.
val options = Map(
"geometry" -> "points",
"colnames" -> "x,y,z",
"coordSys" -> "cartesian",
"gridtype" -> "octree")
// Add a column containing the future partition ID.
// Note that no shuffle has been done yet.
val df_colid = df.prePartition(options, numPartitions=8)
df_colid.show()
+---+---+---+------+------------+
| x| y| z|radius|partition_id|
+---+---+---+------+------------+
|1.0|1.0|1.0| 0.8| 6|
|1.0|1.0|1.0| 0.5| 6|
|3.0|1.0|1.0| 0.8| 7|
|3.0|1.0|1.0| 0.5| 7|
|3.0|3.0|1.0| 0.8| 5|
|3.0|3.0|1.0| 0.5| 5|
|1.0|3.0|1.0| 0.8| 4|
|1.0|3.0|1.0| 0.5| 4|
|1.0|1.0|3.0| 0.8| 2|
|1.0|1.0|3.0| 0.5| 2|
|3.0|1.0|3.0| 0.8| 3|
|3.0|1.0|3.0| 0.5| 3|
|3.0|3.0|3.0| 0.8| 1|
|3.0|3.0|3.0| 0.5| 1|
|1.0|3.0|3.0| 0.8| 0|
|2.0|2.0|2.0| 2.0| 1|
+---+---+---+------+------------+
// Trigger the repartition
val df_repart = df_colid.repartitionByCol("partition_id", preLabeled=true, numPartitions=8)
df_repart.show()
+---+---+---+------+------------+
| x| y| z|radius|partition_id|
+---+---+---+------+------------+
|1.0|3.0|3.0| 0.8| 0|
|3.0|3.0|3.0| 0.8| 1|
|3.0|3.0|3.0| 0.5| 1|
|2.0|2.0|2.0| 2.0| 1|
|1.0|1.0|3.0| 0.8| 2|
|1.0|1.0|3.0| 0.5| 2|
|3.0|1.0|3.0| 0.8| 3|
|3.0|1.0|3.0| 0.5| 3|
|1.0|3.0|1.0| 0.8| 4|
|1.0|3.0|1.0| 0.5| 4|
|3.0|3.0|1.0| 0.8| 5|
|3.0|3.0|1.0| 0.5| 5|
|1.0|1.0|1.0| 0.8| 6|
|1.0|1.0|1.0| 0.5| 6|
|3.0|1.0|1.0| 0.8| 7|
|3.0|1.0|1.0| 0.5| 7|
+---+---+---+------+------------+
preLabeled means the column containing the partition ID contains already numbers from 0 to numPartitions - 1 (see below for the generic case).
Note that you can also use the DataFrame methods as standalone methods (not as DataFrame implicits):
import com.astrolabsoftware.spark3d.Repartitioning.prePartition
import com.astrolabsoftware.spark3d.Repartitioning.repartitionByCol
val df_colid = prePartition(df, options, numPartitions)
val df_repart = repartitionByCol(df_colid, "partition_id", preLabeled, numPartitions)
Options for 3D repartitioning
The current options for spark3D repartitioning are:
gridtype: the type of repartitioning. Available: current (no repartitioning), onion, octree.geometry: geometry of objects: points (3 coordinates), spheres (3 coordinates + radius)coordSys: coordinate system: spherical or cartesiancolnames: comma-separated names of the spatial coordinates. For points, must be “x,y,z” or “r,theta,phi”. For spheres, must be “x,y,z,R” or “r,theta,phi,R”.
For example, to load point-like objects whose column coordinates are (x, y, z), in a cartesian coordinate system and repartition using octree, you would use:
val options = Map(
"geometry" -> "points",
"colnames" -> "x,y,z",
"coordSys" -> "cartesian",
"gridtype" -> "octree")
Create your own Partitioning
spark3D contains limited number of partitioners. We plan to add more (RTree in preparation for example). In the meantime, you can add your partitioner, and use spark3D repartitionByCol to trigger the repartitioning.
Typically, a partitioner is an object which associate to each row a partition ID. So if you come up with your column containing partition ID, the job is done!
Going beyond: column partitioning as a standard Spark SQL method
Actually you do not even need to know or create the underlined partitioners. Say you already have a column that described your partitioning, then you can directly apply repartitionByCol:
// spark3D implicits
import com.astrolabsoftware.spark3d._
df.show()
+---+----+
|Age|flag|
+---+----+
| 20| 0|
| 30| 1|
| 24| 0|
| 56| 0|
| 34| 1|
+---+----+
val df_repart = df.repartitionByCol("flag", preLabeled=true, numPartitions=2)
df_repart.show()
+---+----+
|Age|flag|
+---+----+
| 20| 0|
| 24| 0|
| 56| 0|
| 30| 1|
| 34| 1|
+---+----+
If your columns is not preLabeled (i.e. does not contain partition ID), this is not a problem:
// spark3D implicits
import com.astrolabsoftware.spark3d._
df.show()
+---+----+----+
|Age|flag|part|
+---+----+----+
| 20| 0| A|
| 30| 2| A|
| 24| 0|toto|
| 56| 0| A|
| 34| 2|toto|
+---+----+----+
val df_repart = df.repartitionByCol("part", preLabeled=false)
df_repart.show()
+---+----+----+
|Age|flag|part|
+---+----+----+
| 20| 0| A|
| 30| 2| A|
| 56| 0| A|
| 24| 0|toto|
| 34| 2|toto|
+---+----+----+
df_repart.rdd.getNumPartitions
2
Note however that the execution time will be longer since the routine needs to map column elements to distinct keys.
How is spark3D df.repartitionByCol different from Apache Spark df.repartitionByRange or df.orderBy?
df.repartitionByRangereturns aDataFramepartitioned by the specified column(s).df.orderByreturns aDataFramepartitioned and sorted by the specified column(s).
A major problem of both is there is no guarantee to always get the same final partitioning. In other words, they are non-deterministic. See for example SPARK-26024. For performance reasons they use sampling to estimate the ranges (with default size of 100). Hence, the output may not be consistent, since sampling can return different values.
Conversely df.repartitionByCol always guarantees the same final partitioning, by strictly following the partitioning scheme in the specified column. Obviously this exactness has a cost, and using df.repartitionByCol can increase the repartitioning time as shown in:
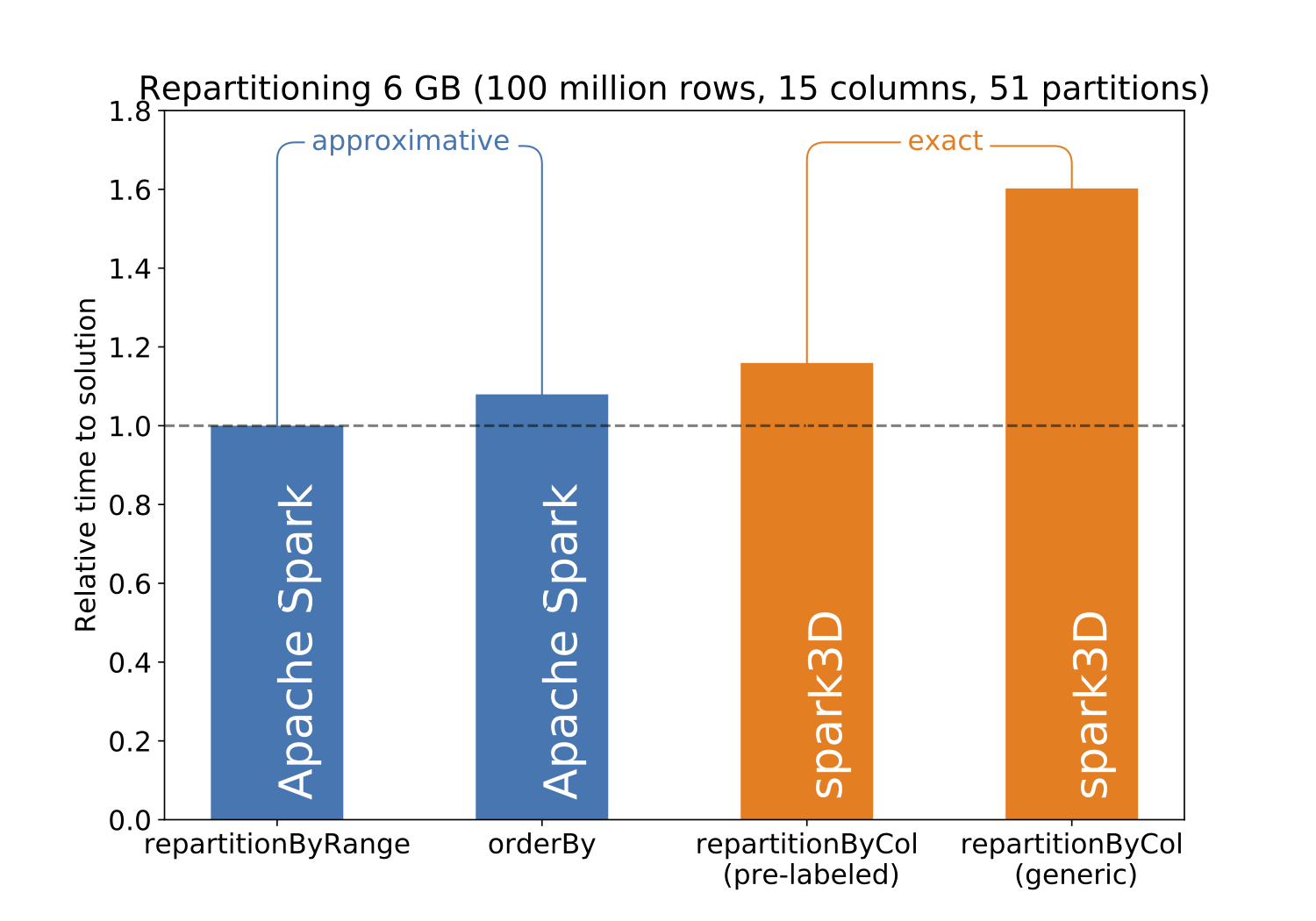
Note that the Spark df.repartition method is not present from this benchmark as for such volume of data it leads to completely unpredictive results (empty partitions, and partitions twice the size of others… even by fixing the number of partitions AND the column to use for the repartitioning).
Memory and speed considerations
We advice to cache the re-partitioned sets, to speed-up future call by not performing the re-partitioning again.
However keep in mind that if a large numPartitions decreases the cost of performing future queries (cross-match, KNN, …), it increases the partitioning cost as more partitions implies more data shuffle between partitions. There is no magic number for numPartitions which applies in general, and you’ll need to set it according to the needs of your problem.
What kind of performance I will get assuming fixed cluster configuration and input data set?
Assuming you use a fix cluster configuration (numbers of cores + available memory), the repartitioning time is quadratic in the final number of partitions:
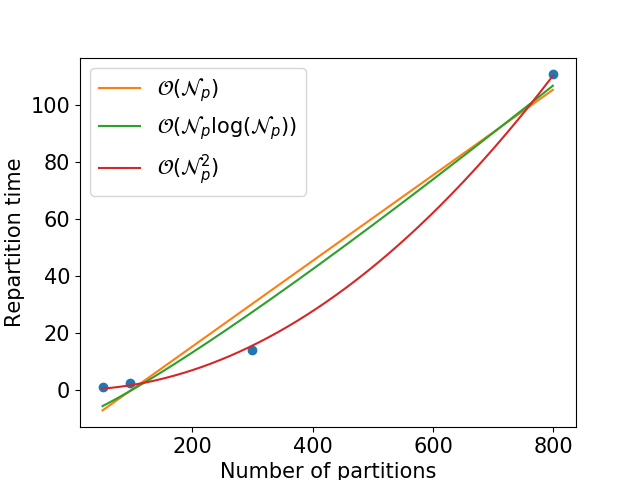
In fact, that also depends on the difference between the number of worker threads and the number of partitions:
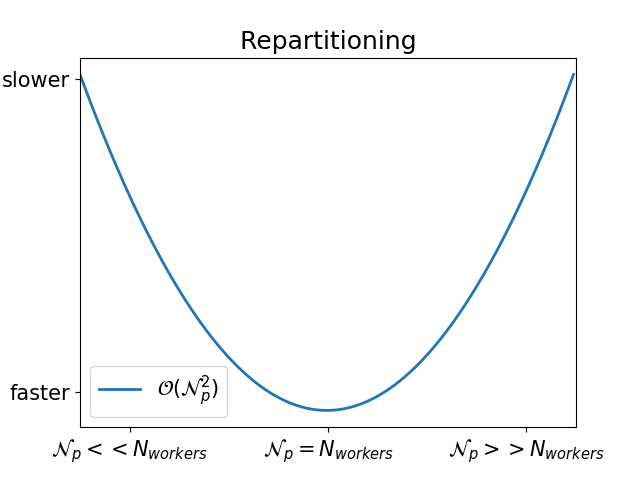
How can I check that my repartitioning is well balanced?
There is a method in spark3D to check the load balancing:
import com.astrolabsoftware.spark3d.Checkers.checkLoadBalancing
df_repart.checkLoadBalancing("frac").show()
+--------+------------+
|Load (%)|partition_id|
+--------+------------+
| 10.52| 0|
| 10.19| 1|
| 9.925| 2|
| 9.87| 3|
| 10.135| 4|
| 10.13| 5|
| 9.49| 6|
| 9.81| 7|
| 9.87| 8|
| 10.06| 9|
+--------+------------+